¶ Hello World
本文从“大数据的 Hello World”开始,去学习怎么在 Spark 之上做应用开发。不过,“大数据的 Hello World”并不是把字符串打印到屏幕上这么简单,而是要先对文件中的单词做统计计数,然后再打印出频次最高的 5 个单词,江湖人称“Word Count”。
¶ Spark安装部署
首先要确保完成Spark本地部署,可以参考 Spark部署教程。安装完成后,在命令行终端中输入 spark-shell --version来验证部署是否完成。
¶ Word Count实现
- 程序目标:对文件中的单词做统计计数,打印出频次最高的5个词汇。
- 数据集:实验文本 wikiOfSpark.txt
¶ 计算过程
- 读取内容:调用 Spark 文件读取 API,加载 wikiOfSpark.txt 文件内容;
- 分词:以行为单位,把句子打散为单词;
- 分组计数:按照单词做分组计数。
¶ 代码实现
¶ 1.内容读取
首先,调用 SparkContext 的 textFile 方法,读取源文件,也就是 wikiOfSpark.txt,代码如下表所示:
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
其中,spark 和 sparkContext 分别是两种不同的开发入口实例:
- spark 是开发入口 SparkSession 实例(Instance),SparkSession 在 spark-shell 中会由系统自动创建;
- sparkContext 是开发入口 SparkContext 实例。
在 Spark 版本演进的过程中,从 2.0 版本开始,SparkSession 取代了 SparkContext,成为统一的开发入口。换句话说,要开发 Spark 应用,你必须先创建 SparkSession。
RDD 的全称是 Resilient Distributed Dataset,意思是“弹性分布式数据集”。RDD 是 Spark 对于分布式数据的统一抽象,它定义了一系列分布式数据的基本属性与处理方法。
¶ 2.分词
“分词”就是把“数组”的行元素打散为单词。要实现这一点,我们可以调用 RDD 的 flatMap 方法来完成。flatMap 操作在逻辑上可以分成两个步骤:映射和展平。
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
- 映射指对每行元素的分割操作,利用分隔符将元素从String变为Array[String]
- 展平指去掉内层的嵌套结构,从“二维数组”变为“一维数组”
值得注意的是,我们用“空格”去分割句子,有可能会产生空字符串。所以,在完成“映射”和“展平”之后,对于这样的“单词”,我们要把其中的空字符串都过滤掉,这里我们调用 RDD 的 filter 方法来过滤:
// 过滤掉空字符串
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
¶ 分组计数
在 RDD 的开发框架下,聚合类操作,如计数、求和、求均值,需要依赖键值对(Key Value Pair)类型的数据元素,也就是(Key,Value)形式的“数组”元素。
因此,在调用聚合算子做分组计数之前,要先把 RDD 元素转换为(Key,Value)的形式,也就是把 RDD[String]映射成 RDD[(String, Int)]。其中,统一把所有的 Value 置为 1。这样一来,对于同一个的单词,在后续的计数运算中,只要对 Value 做累加即可。
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
分组计数其实是两个步骤,也就是先“分组”,再“计数”。下面,使用聚合算子 reduceByKey 来同时完成分组和计数这两个操作。
对于 kvRDD 这个键值对“数组”,reduceByKey 先是按照 Key(也就是单词)来做分组,分组之后,每个单词都有一个与之对应的 Value 列表。然后根据用户提供的聚合函数,对同一个 Key 的所有 Value 做 reduce 运算。
这里的 reduce,你可以理解成是一种计算步骤或是一种计算方法。当我们给定聚合函数后,它会用折叠的方式,把包含多个元素的列表转换为单个元素值,从而统计出不同元素的数量。
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
我们传递给 reduceByKey 算子的聚合函数是 (x, y) => x + y,也就是累加函数。因此,在每个单词分组之后,reduce 会使用累加函数,依次折叠计算 Value 列表中的所有元素,最终把元素列表转换为单词的频次。对于任意一个单词来说,reduce 的计算过程都是一样的,如下图所示。
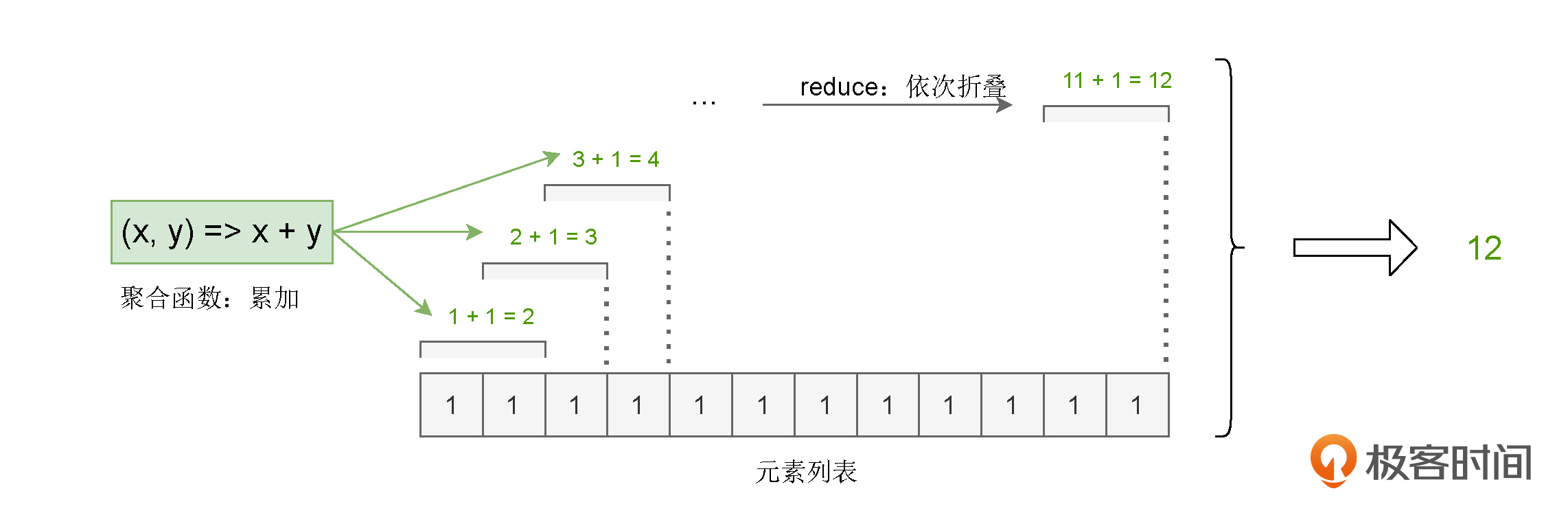
在程序的最后,我们还要把 wordCounts 按照词频做排序,并把词频最高的 5 个单词打印到屏幕上,代码如下所示。
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
完整代码如下:
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
¶ 程序运行
- 打开命令行终端(Terminal),敲入“spark-shell”,打开交互式运行环境
- 把开发好的代码,依次敲入 spark-shell
- 我们把上面的代码依次敲入到 spark-shell 之后,spark-shell 最终会把词频最高的 5 个单词打印到屏幕上:
