¶ 技术架构
¶ 什么是推荐系统?
- 推荐系统:在“信息过载”的情况下,用户如何高效获取感兴趣的信息?
- 推荐系统待解决的问题:对于用户U(User),在特定场景C(Context)下,针对海量的“物品”信息构建一个函数,预测用户对特定候选物品I(Item)的喜好程度,再根据喜好程度对所有候选物品进行排序,生成推荐列表的问题。

其中,抽象函数 (U,I,C) 被称为推荐系统模型,负责“猜测”用户的心,为用户可能感兴趣的物品打分,从而得出最终的推荐物品列表。
¶ 深度学习推荐系统
¶ 为什么引入深度学习?
深度学习复杂的模型结构,让深度学习模型具备了理论上拟合任何函数的能力
¶ 推荐系统技术架构

¶ 数据部分
负责“用户”、“物品”、“场景”信息的收集与处理。按照实时性的强弱排序,可以分为客户端与服务器端实时数据处理、流处理平台准实时数据处理、大数据平台离线数据处理。在实时性由强到弱递减的同时,三种平台的海量数据处理能力则由弱到强。因此,一个成熟推荐系统的数据流系统会将三者取长补短,配合使用。
用户:包括历史行为、人口属性、关系网络等
物品:推荐的场景,如新闻、视频、商品等
场景:上下文信息,包括时间、地点、用户状态等
大数据计算平台通过对推荐系统日志,物品和用户的元数据等信息的处理,获得了推荐模型的训练数据、特征数据、统计数据等。大数据平台加工后的数据出口主要有 3 个:
- 生成推荐系统模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐系统模型服务(Model Serving)所需的“用户特征”,“物品特征”和一部分“场景特征”,
- 用于推荐系统的线上推断。生成系统监控、商业智能(Business Intelligence,BI)系统所需的统计型数据。
¶ 模型部分
推荐系统的“模型部分”是推荐系统的主体。模型的结构一般由召回层、排序层以及补充策略与算法层组成。
- 召回层:一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。
- 排序层:利用排序模型对初筛的候选集进行精排序。
- 补充策略与算法层:也被称为“再排序层”,是在返回给用户推荐列表之前,为兼顾结果的“多样性”“流行度”“新鲜度”等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
从推荐系统模型接收到所有候选物品集,到最后产生推荐列表,这一过程一般叫做“模型服务过程”。为了生成模型服务过程所需的模型参数,我们需要通过模型训练(Model Training)确定模型结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。
模型的训练方法根据环境的不同,可以分为“离线训练”和“在线更新”两部分。其中,离线训练的特点是可以利用全量样本和特征,使模型逼近全局最优点,而在线更新则可以准实时地“消化”新的数据样本,更快地反应新的数据变化趋势,满足模型实时性的需求。
除此之外,为了评估推荐系统模型的效果,以及模型的迭代优化,推荐系统的模型部分还包括“离线评估”和“线上 A/B 测试”等多种评估模块,用来得出线下和线上评估指标,指导下一步的模型迭代优化。
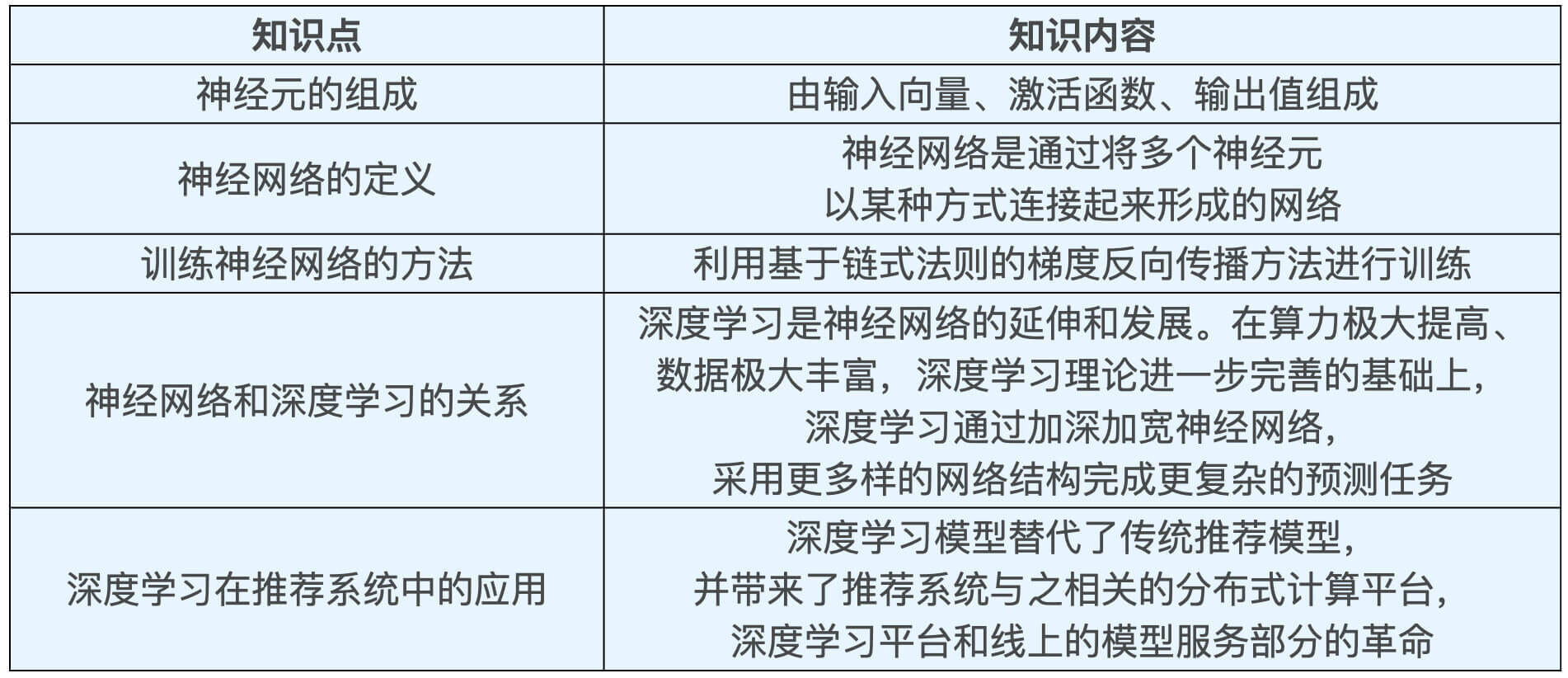
¶ 深度学习的应用
- 深度学习中 Embedding 技术在召回层的应用。作为深度学习中非常核心的 Embedding 技术,将它应用在推荐系统的召回层中,做相关物品的快速召回,已经是业界非常主流的解决方案了。
- 不同结构的深度学习模型在排序层的应用。排序层(也称精排层)是影响推荐效果的重中之重,也是深度学习模型大展拳脚的领域。深度学习模型的灵活性高,表达能力强的特点,这让它非常适合于大数据量下的精确排序。深度学习排序模型毫无疑问是业界和学界都在不断加大投入,快速迭代的部分。
- 增强学习在模型更新、工程模型一体化方向上的应用。增强学习可以说是与深度学习密切相关的另一机器学习领域,它在推荐系统中的应用,让推荐系统可以在实时性层面更上一层楼。
深度学习基础知识点击 👉🏻 深度学习基础
¶ Sparrow RecSys 项目实战
¶ 项目导入
项目导入:
git clone https://github.com/wzhe06/SparrowRecSys.git
¶ 功能介绍
运行主函数 com.wzhe.sparrowrecsys.online.RecSysServer,打开6010端口即可查看前端效果。

Sparrow RecSys,全称 Sparrow Recommender System,中文名“麻雀推荐系统”,名字取自“麻雀虽小,五脏俱全”之意。
Sparrow RecSys 是一个电影推荐系统,具备“相似推荐”“猜你喜欢”等经典的推荐功能,在页面设置上,主要由“首页”“电影详情页”和“为你推荐页”组成。
Sparrow RecSys 的首页由不同类型的电影列表组成,当用户首次访问首页时,系统默认以历史用户的平均打分从高到低排序,随着当前用户不断为电影打分,系统会对首页的推荐结果进行个性化的调整,比如电影类型的排名会进行个性化调整,每个类型内部的影片也会进行个性化推荐。
其次,是电影详情页。

可以看到电影详情页除了罗列出电影的一些基本信息,最关键的部分是相似影片的推荐。相似内容推荐是几乎所有推荐系统非常重要的功能,传统的推荐系统基本依赖于基于内容(Content based)的推荐方法。
最后,是为你推荐页。

这一部分也是整个推荐系统中最重要的部分,是用户的个性化推荐页面。这个页面会根据用户的点击、评价历史进行个性化推荐。这几乎是所有推荐系统最经典和最主要的应用场景。我希望在这门课程中,你能够动手完成个性化推荐中的每个关键步骤,包括但不限于特征的处理、候选集的召回、排序层主要模型等等。
¶ 数据集
- 数据来源:MovieLens
MovieLens 的数据集包括三部分,分别是 movies.csv(电影基本信息数据)、ratings.csv(用户评分数据)和 links.csv(外部链接数据)
- movies.csv:movies 表是电影的基本信息表,它包含了电影 ID(movieId)、电影名(title)、发布年份以及电影类型(genres)等基本信息。
- ratings.csv:ratings 表包含了用户 ID(userId)、电影 ID(movieId)、评分(rating)和时间戳(timestamp)等信息。评论数据集是之后推荐模型训练所需的训练样本来源,也是分析用户行为序列、电影统计型特征的原始数据。
- links.csv:links 表包含了电影 ID(movieId)、IMDB 对应电影 ID(imdbId)、TMDB 对应电影 ID(tmdbId)等信息。imdb 和 tmdb 是全球最大的两个电影数据库。links 表包含了 MovieLens 电影和这两个数据库 ID 之间的对应关系,可以根据这个对应关系来抓取电影的其他相关信息。
¶ Sparrow Recsys技术架构

涉及到的技术栈如下:

Spark: 当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。常用于迭代计算、交互式计算和流计算领域。
Flink:开源的流批一体分布式计算框架,具备高吞吐、低延迟、精确一次语义等特性,广泛应用于实时数据分析、ETL、欺诈检测等场景。
Redis:开源的、高性能的键值对内存数据库,支持多种数据结构(如字符串、哈希、列表等),具备持久化功能,常用于缓存、消息队列、分布式锁等场景以提升系统性能和处理效率。
HDFS:Apache Hadoop 项目的分布式文件系统,具有高容错、高可扩展性特点,适合存储大规模数据集,可将大文件切分存储在多个节点,广泛用于大数据存储与处理场景。
Spark MLlib:Apache Spark中的可扩展机器学习库,它提供了常见机器学习算法和实用工具,支持多种数据类型和分布式计算,基于 Spark 的内存计算能力,能高效处理大规模数据集,涵盖分类、回归、聚类等众多机器学习任务,且兼容多种编程语言,方便开发者进行模型开发与训练。
TensorFlow:谷歌开源的端到端开源机器学习平台,具备灵活的架构,支持在多种设备与环境运行,提供丰富的工具、库和社区资源,可助力开发者高效构建、训练和部署从简单到复杂的各类机器学习和深度学习模型,广泛应用于图像识别、自然语言处理等诸多领域。
MLeap:一个用于跨平台部署机器学习模型的工具包,它允许用户将训练好的模型(如 Spark ML、Scikit - learn 等模型)进行序列化和打包,实现模型在不同环境(包括低资源环境)间的无缝移植与高效执行,简化了模型从训练到生产部署的流程。
TensorFlow serving:谷歌开源的高性能机器学习模型服务系统,支持多版本模型管理,能灵活部署在不同环境,可高效处理大量预测请求以满足生产需求。
Jetty:一款开源的轻量级Java HTTP服务器、客户端及Servlet容器,采用模块化设计,支持多种协议,启动快且资源占用少。